■後藤弘茂のWeekly海外ニュース■
GPU命令のx86体系への統合
●GPUのネイティブ命令セットの露出がカギ
AMDは、2009年に投入するFUSIONプロセッサでGPUコアをCPUに統合しようとしている。しかし、FUSIONのポイントはハードウェア上でのGPUコアの統合ではない。その先に見える、命令セットレベルでの統合が、FUSIONの最大のポイントだ。AMDは、FUSION世代までに、GPUコアに、ソフトウェアがもっとダイレクトにアクセスできるように道を整えようとしている。
それはGPUコアを、より汎用的なコンピューティングに使うためだ。
 |
| AMDのPhil Hester氏 |
「いったんGPUが統合されると、GPUを汎用化して、より広いメディアプロセッシングや科学技術コードなどのかなりの部分を扱うことが可能になるだろう。グラフィックスだけでなく、より汎用的なアプリケーションを実行できるようになると考えている」とAMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は語る。
ビデオのエンコードに代表されるメディアプロセッシングや、物理シミュレーションのようなHPC的なタスク、データマイニングや音声などの合成などがGPUのアプリケーションとして期待されている。そのためには、GPUに現在よりダイレクトにアクセスできる方法が必要になる。
では、AMDはFUSIONでは、GPU命令をどのような形態でビジブル(アクセス可能な状態)にするつもりなのだろう。FUSION世代のGPUプログラミングのオープン化のポイントは次の2つだ。
(1)GPUのネイティブ命令セットを完全にオープンにし、将来に渡って一貫性を維持するのかどうか
(2)GPU命令をx86命令セットアーキテクチャ(ISA:Instruction Set Architecture)に取り込むのかどうか
現在のGPUは、世代毎にマイクロアーキテクチャを大きく変更している。そのため、GPUのネイティブ命令セットは、メーカー毎に異なるだけでなく、同じメーカーでもGPU世代によっても異なっている。GPUでは、ソフトウェア層でラップすることでネイティブ命令セットを隠蔽することを大前提としているから、こうしたモデルを採ることが可能だ。
だが、こうした構造から、GPUへのダイレクトアクセスにも現状では限界がある。例えば、NVIDIAの「CUDA (クーダ:compute unified device architecture)」汎用プログラミングモデルの場合も、真にダイレクトというわけではない。グラフィックス用のDirectXなどよりも、薄く汎用的なランタイムソフトウェアをCPU上で走らせ、ダイレクトに近いアクセスを実現している。AMD(ATI)の「Close to the Metal(CTM)」のようにより低レベルで露出された場合も、その命令アーキテクチャが将来も継続されるかどうかが今1つ明確ではなかった。また、CPUのようにプログラミング情報が広く公開されているわけでもない。
そのため、FUSIONではAMDがどんなアプローチを取るのかが大きなポイントとなる。
もう1つのポイントは、GPUコアの命令セットを公開するとしたら、その命令セットをx86命令セットのフォーマットの中に取り込んでしまうのか、それとも独立した命令セットとして実装するのかという点。これもそれぞれ利点と不利点のトレードオフがあるので、難しい。
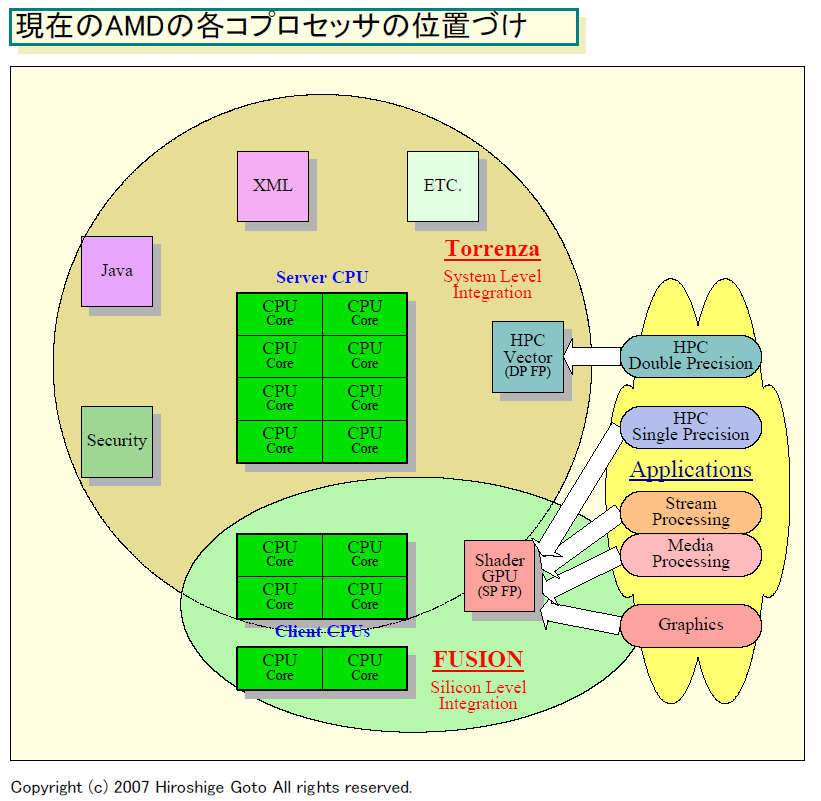 |
| AMD Mobile Platform Roadmap(※別ウィンドウで開きます) PDF版はこちら |
●GPU命令セットをビジブルにする
AMDのFUSIONビジョンが優れているのは、これらのポイントについても、展望を持っている点だ。まず、2006年12月のAnalyst Dayでは、Hester氏はネイティブ命令セットの公開は明確にしている。
「新たにネイティブモード命令セットを露出させると、アプリケーションがどんどんGPUの機能を使うようにリコンパイルされて行くだろう」
また、Hester氏は2006年のインタビューでも答えている。
「GPU機能を統合するなら、人々は(GPUコアに)もっとスタンダードな方法でアクセスしたいと考えるだろう。そこで、GPU機能を、ユーザーモード命令セットとして、適切にビジブルにすることができると思う。ビジブルなGPU命令を一貫性を持って将来にも提供する。それによって、x86アーキテクチャを、32-bitから64-bitへの前進の時と同じような方法で、前進させることができると私は信じている」(Hester氏)
AMDは、方向性としてはGPUネイティブ命令セットの露出化へと向かっている。同じGPU命令セットを継続して提供・発展させることで、一貫したプログラミングモデルを提供しようとしている。従来のGPUとは明確な違いだ。
このことは、GPUの方向性を大きく変える要素を持っている。というのは、従来のように命令セットの継続性を無視したGPUアーキテクチャの拡張ができなくなるからだ。CPUのように、命令セットの一貫性を保ちながら発展される方向へと、将来のAMD GPUコアは向かうことになりそうだ。つまり、GPUアーキテクチャの開発の手法が大きく変わるわけだ。
その一方で、命令セットの一貫性が保たれることでソフトウェア層の開発が容易になる。あるGPU世代向けに開発したネイティブコードのソフトウェアが、そのまま将来のGPUでも走ることが保証されるからだ。コードの最適化も容易になる。
そして、このことは次の命令セット戦争を予見させる。各社のGPUのネイティブ命令が異なっているため、例え全てのGPUベンダーが命令セットを公開したとしても、バイナリ互換性はない。そのため、アプリケーション側がGPUとネイティブ命令を使い始めたら、命令セット同士の戦いとなり始める。SSE対3DNow!のような命令セット争いが再び起こる可能性がある。しかし、今回は64-bit化でのx86-64(AMD64)対Yamhillの時にように、先行するAMDの側が有利になる可能性も高い。また、敵はIntelではなく、NVIDIAかもしれない。
●CPUのユーザーモード命令セットとして統合
また、AMDのFUSIONでの命令セットのビジブル化では、CPUの命令セットアーキテクチャの中にGPU命令を取り込むことが適切だと考えていることもポイントだ。Hester氏のビジョンをもう少し詳しく説明すると次のようになる。
「一般論として、コプロセッサの統合には2つの方法がある。1つは、CPUのユーザーモード命令セットアーキテクチャに統合してしまう方法、もう1つは一種のシステムリソースとして、デバイスドライバなどを経由して扱う方法。これらには、それぞれ利点と不利がある。
まず、ユーザーモード命令セットの中に統合するためには、(CPUメーカーが)特定の機能とアーキテクチャについて、今後も発展させ続けることを(ユーザーに対して)正当化できなければならない。
命令セットアーキテクチャに取り入れることの利点は、非常に低いオーバーヘッドコストでその機能を使うことができるようになること。一方、不利な点は、その命令を保証するなら、今後も常に(その命令で使える)機能をシリコンに入れ続けなければならないことだ。
だから、統合するかどうかの判断は、非常に慎重に行なう必要がある。また、今後も、(統合するコプロセッサの)アーキテクチャを論理的に一貫性の取れた方法で進化させる必要がある。そうした条件が満たされれば、ユーザーモード命令セットに加えることを正当化できるだろう。
場合によっては、正しい答えはTorrenza型のコプロセッサでのデバイスドライバ型構造となるケースもあると思う。特殊なアプリケーションがそのコプロセッサ命令でプロセッシングするものの、ベースアーキテクチャに命令を入れるほど正当化できないケースがあるだろう。そうした機能は、Torrenza型のコプロセッサで扱う要素の1つになると考えている。Torrenza型の場合は、デバイスドライバ型のストラクチャを通じて、ソフトウェアとコミュニケーションするだろう。
どちらが適切かは、一種のティッピングポイント(Tipping Point:しきい値)の議論となる」
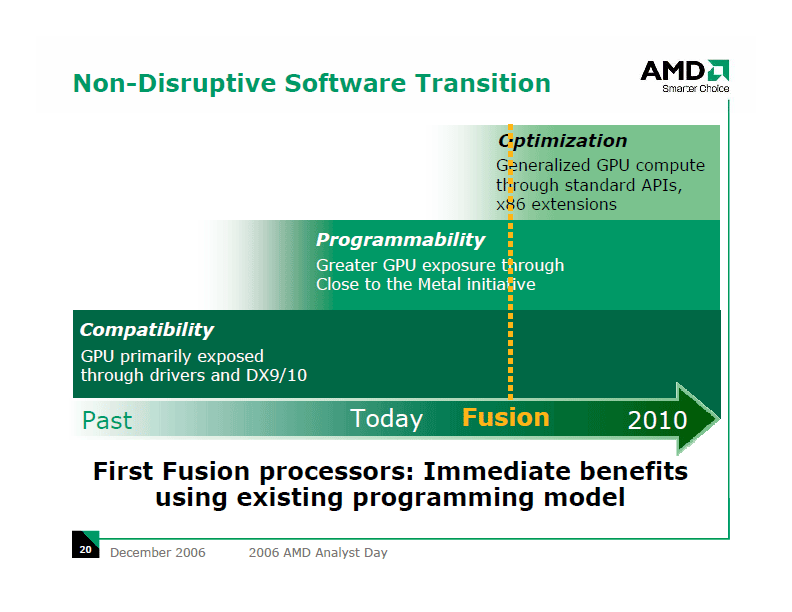 |
| Non-Disruptive Software Transition (※別ウィンドウで開きます) PDF版はこちら |
●GPUを命令セットレベルでCPUに統合して行く
AMDは、どうせGPU命令セットを露出させるなら、x86のベースフォーマットの中に、ユーザーモードの拡張命令として組み込もうというビジョンを持っているようだ。これは、より基本的なレベルでのCPUとGPUの統合を考えていることを示している。このモデルでは、x86命令のストリームに組み込まれたGPU命令をデコーダがデコード、GPUコアに発行すると推測される。
現在は、CPU上のランタイムがグラフィックス命令やGPU向け汎用命令をリアルタイムでGPUネイティブ命令に変換。変換の終わったネイティブ命令を、バスを経由してGPUに送り込んでいる。しかし、命令セットの統合後は、CPUの命令デコーダで直接GPUネイティブ命令がデコードされるようになる。その場合、最終的にはGPUコアは、CPUの中のGPU機能へと融合されて行くだろう。
TorrenzaとFUSIONには、このようにオンチップかオフチップかという違い以上に、ソフトウェア面での違いがある。
しかし、この構想では、ただでさえ複雑なx86命令セット体系をさらに複雑にし、その結果、命令デコーダの負担も増やすことを意味する。これは問題ではないのだろうか。
「x86のユーザーモード命令セットフォーマットには、まだ十分なオペコードポイントが残されている。エクステンションで、命令を加えることが可能だ。また、命令デコーダは現状でもすでに複雑だ。だから、さらに複雑性を加えても、比較的小さい変化でしかない。エンジニアは十分に可能だと言っている。
だから、我々は、この種の問題については、それほど心配していない。それよりも重要な問題は、どんな命令をユーザーモード命令セットに加えるべきかという点だ。いったん加えた(コプロセッサ)命令の機能は、常にサポートし続けることをコミットしなければならない。だから慎重に行なう必要がある」(Hester氏)
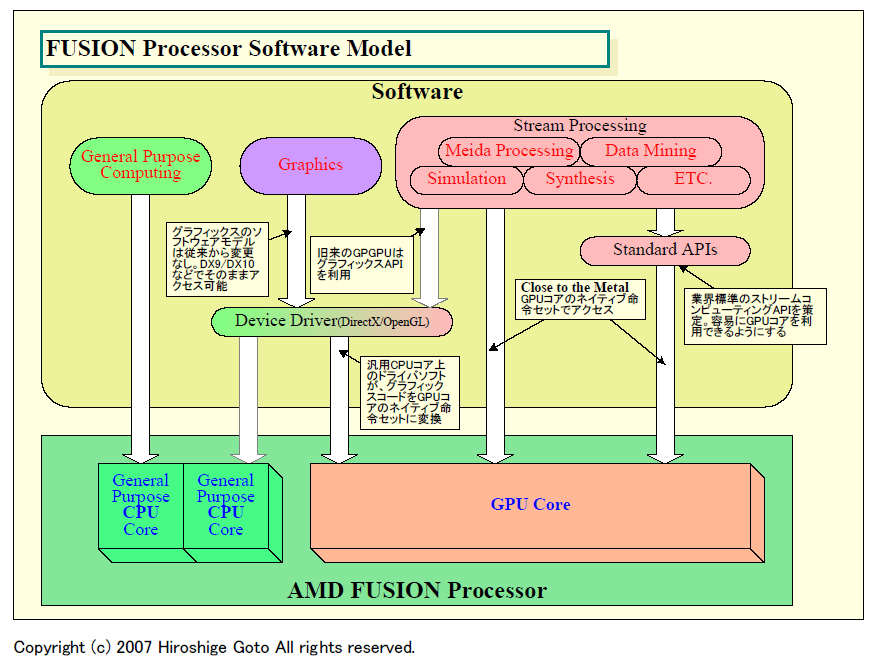 |
| FUSION Processor Software Model (※別ウィンドウで開きます) PDF版はこちら |
●x86 CPU側からは不可視のTorrenza型コプロセッサ
AMDは、すでに複雑なx86アーキテクチャだから、それを拡張するなら問題はないと見ていることがわかる。実際、プリフィックス等で複雑化した可変長の命令セットは、現状でも命令デコーダにとってとてつもない重荷となっている。これを変革するには、x86命令セット自体を一新する以外の方法はない。それなら、現状の複雑度にさらにちょっと複雑性を加えても、大きな変化ではないという判断だと推測される。
ただし、いったんサポートした命令は簡単に切り捨てられなくなってしまう。だから、x86命令セット体系に取り込む命令は、慎重に選ぶ必要がある。利点は大きいが、命令セットを統合できるコプロセッサは限られる。
一方、Torrenzaのデバイスドライバモデルでは、オーバーヘッドはあるが、ソフトウェア的には容易な統合となる。コプロセッサ側の命令セットのフォーマットも、自由にできるという利点もある。例えば、コプロセッサではVLIW(Very Long Instruction Word)型命令セットを取ることもできる。
「Torrenza型でデバイスドライバを経由する場合は、データは(ホストプロセッサから)コプロセッサにそのままパスされる。データフォーマットはコプロセッサ独自で構わないので、他との互換性について心配する必要はない。
x86プロセッサ側から見ると、コントロールブロック(プログラム)は単にデータで、決してx86プロセッサ上で実行されることはない。(コプロセッサの)命令フォーマットやその他の要素は、x86プロセッサからは不可視で、コプロセッサからしか見えない。だから、コントロールブロックは、どんなフォーマットに定義することも可能で、コプロセッサとしてベストな設計にできる」とHester氏は説明する。
 |
| Continuum of Solution (※別ウィンドウで開きます) PDF版はこちら |
●CPUとGPUの物理的な統合と命令レベルの統合の連携
この場合、ポイントの1つはCPUとGPUのオンダイ統合が、命令セットの複合を意味するわけではないという点だ。単一ダイ上にまとめたとしても、両コアの命令セットをTorrenza型に別々に実装することはできる。システムオンチップ(SoC)アプローチで、単純にダイ上にCPUとGPUを配置するだけなら、命令レベルの統合は必要とされない。一方、逆にダイは別でも命令セット的には統合された形態もありうる。
しかし、CPUとGPUのシリコン上での統合化が、命令セットの統合の重要なキーであるのは確かだ。
「CPUとGPUを統合することで、初めて機能を(ユーザーに)保証して『よし、これで、ユーザーモード命令セットに入れ込むことを正当化できる』と決定できるようになる」とHester氏は語る。
つまり、AMDはコプロセッサのオンダイ統合が、命令セットレベルの統合の条件と考えている。
もっとも、実際の製品レベルでは、GPUコアの物理的な統合と、命令セット上の統合は時期がずれるかもしれない。また、GPUコアのマイクロアーキテクチャ上の統合も、命令セットレベルの統合にともなって、段階的に変化して行く可能性がある。最初は、GPUコアがCPUコアとは分離され内部クロスバーで接続された形態だが、将来は、もっと融合が進んだアーキテクチャへと変わって行く可能性がある。
AMDのビジョンに沿って行くと、FUSION世代の将来のGPUコアのソフトウェアモデルは、CPUのそれに似てくる。ネイティブ命令セットがビジブルになっていて、x86フォーマットに取り込まれ、一貫性を持って命令が保持されて行く。当然、その上で各種ミドルウェアが成長し、アプリケーションがGPU機能を容易に使えるようになって行くことが予想される。
PCのソフトウェアモデルの場合、こうしたミドルウェアが確立しないと、なかなか普及が進まない。そのため、標準的なAPIの整備などが重要となる。ここで、要となる存在が、Microsoftなのか、それともOpenGL ESなどを策定する団体Khronos Groupなのか、あるいはPeakStreamのようなベンチャーなのか、まだわからない。しかし、AMDは、リーダーシップを取って行く必要があることだけは確かだ。
問題はここにある。AMDが苦手なことの1つが、ソフトウェア面でのリーダーシップを取って行くことだからだ。GPUコアの統合で、チップレベルの統合以上に困難なのは、おそらく、こうしたソフトウェア面の整備だ。FUSIONが、AMDにとって大きなチャレンジであるのは、この点だ。
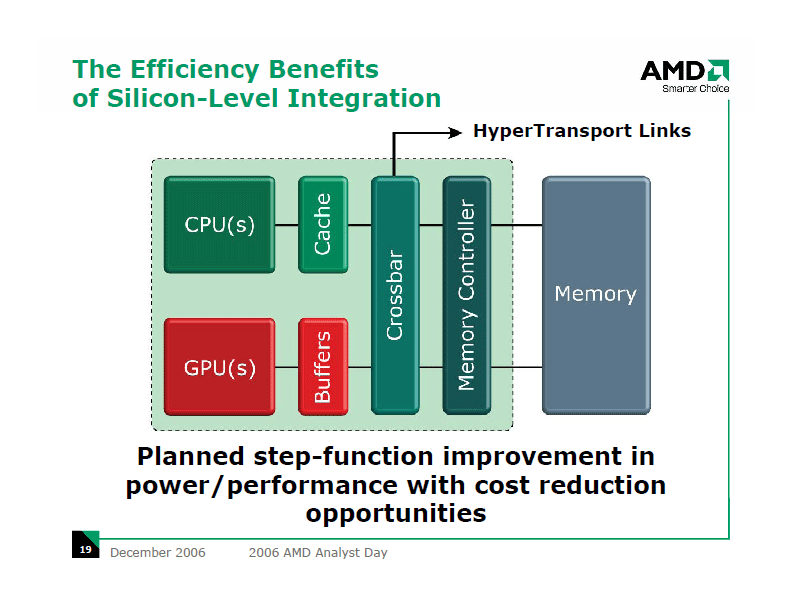 |
| The Efficiency Benefits of Silicon-Level Integration (※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【2007年2月27日】【海外】CPUとGPUの統合プロセッサのチャレンジ
http://pc.watch.impress.co.jp/docs/2007/0227/kaigai340.htm
【2007年2月15日】【海外】Intelの次世代CPU「Wolfdale」と「CPU+GPU」
http://pc.watch.impress.co.jp/docs/2007/0202/kaigai333.htm
【1月22日】【海外】AMDが“Fusion”プロセッサとオクタコアに進む理由
http://pc.watch.impress.co.jp/docs/2007/0122/kaigai330.htm
(2007年2月28日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
■고토 히로시무의 Weekly 해외 뉴스■
GPU 인스트럭션의 x86 체계에의 통합
●GPU의 네이티브 인스트럭션 세트의 노출이 열쇠
AMD는 2009년에 투입하는 FUSION 프로세서로 GPU 코어를 CPU에 통합하려고 하고 있다. 그러나 FUSION의 포인트는 하드웨어상 에서의 GPU 코어의 통합은 아니다. 그 전에 인스트럭션 세트 레벨에서의 통합이 FUSION의 최대의 포인트다. AMD는 FUSION 세대까지 GPU 코어에 소프트웨어가 좀 더 다이렉트 하게 액세스 할 수 있도록 길을 정돈하려 하고 있다.
그것은 GPU 코어를 보다 범용적인 컴퓨팅에 사용하기 위해서다.
AMD의 Phil Hester 는
「일단 GPU가 통합되면 GPU를 범용화해서 보다 넓은 미디어 프로세싱이나 과학기술 코드등의 상당한 부분을 취급하는 것이 가능하게 될 것이다. 그래픽 뿐만이 아니라 보다 범용적인 어플리케이션을 실행할 수 있게 된다고 생각하고 있다」라고 AMD의 Phil Hester (Senior Vice President & Chief Technology Officer(CTO))는 말한다.
비디오의 encode로 대표되는 미디어 프로세싱이나 물리 시뮬레이션과 같은 HPC 작업 데이터 마이닝(data mining)이나 음성등의 합성등이 GPU의 어플리케이션으로서 기대되고 있다. 그 때문에 GPU에 현재보다 다이렉트 하게 액세스 해야하는 방법이 필요하게 된다.
그럼 AMD는 FUSION에서는 GPU 인스트럭션을 어떠한 형태로 액세스 가능한 상태로 할 생각인가. FUSION 세대의 GPU 프로그래밍의 오픈화의 포인트는 다음의 2개다.
(1) GPU의 네이티브 인스트럭션 세트를 완전하게 오픈해서 장래에도 일관성을 유지하는지 어떤지
(2) GPU 인스트럭션을 x86 인스트럭션 세트 아키텍쳐(ISA:Instruction Set Architecture)수중에 넣는지 어떤지
현재의 GPU는 세대마다 마이크로 아키텍쳐를 크게 변경하고 있다. 그 때문에 GPU의 네이티브 인스트럭션 세트는 메이커마다 다를 뿐만 아니라 같은 메이커에서도 GPU 세대에 의해서 차이가 난다. GPU에서는 소프트웨어층 에서 랩 하는 것으로 네이티브 인스트럭션 세트를 은폐 하는 것을 대전제로 하고 있기 때문에 이러한 모델을 뽑는 것이 가능하다.
하지만, 이러한 구조로부터 GPU에의 다이렉트 액세스에도 현재 상태로서는 한계가 있다. 예를 들면, NVIDIA의 「CUDA (compute unified device architecture)」범용 프로그래밍 모델의 경우도 실제로는 다이렉트 하는 것은 아니다. 그래픽용의 DirectX 보다 얇게 범용적인 런타임 소프트웨어를 CPU상에서 실행하게 해서 다이렉트에 가까운 액세스를 실현하고 있다. AMD(ATI)의 「Close to the Metal(CTM)」와 같이 보다 낮은수준으로 노출되었을 경우도 그 인스트럭션 아키텍쳐가 장래에도도 계속될지 어떨지가 지금 명확하지 않다. 또, CPU와 같이 프로그래밍 정보가 넓게 공개되고 있는 것도 아니다.
그 때문에, FUSION에서는 AMD가 어떤 어프로치를 취하는지가 큰 포인트가 된다.
이제 1개의 포인트는, GPU 코어의 인스트럭션 세트를 공개한다고 하면, 그 인스트럭션 세트를 x86 인스트럭션 세트의 포맷안에 수중에 넣어 버리는지, 그렇지 않으면 독립한 인스트럭션 세트로서 실행하는가 하는 점. 이것도 각각 이점과 단점의 트레이드 오프가 있으므로 어렵다.
●GPU 인스트럭션 세트를 가능하게 한다
AMD의 FUSION 비전이 우수한 것은, 이러한 포인트에 대해서도, 전망을 가지고 있는 점이다. 우선, 2006년 12월의 Analyst Day에서는, Hester 는 네이티브 인스트럭션 세트의 공개를 명확하게 하고 있다.
「새롭게 native mode 인스트럭션 세트를 노출시키면 어플리케이션이 자꾸자꾸 GPU의 기능을 사용하도록 recompile 되어 갈 것이다」
또, Hester 는 2006년의 인터뷰에서도 대답하고 있다.
「GPU 기능을 통합한다면, 사람들은(GPU 코어에) 좀 더 표준적인 방법으로 액세스 하고 싶다고 생각할 것이다. 거기서, GPU 기능을 유저 모드 인스트럭션 세트로서 적절히 사용 가능하게 할 수 있다고 생각한다. 사용가능한 GPU 인스트럭션이 장래에도 일관성있게 제공한다. 거기에 따라, x86 아키텍쳐를, 32-bit로부터 64-bit에의 이행 때와 같은 방법으로, 전진시킬 수가 있다고 나는 믿고 있다」(Hester)
AMD는 방향성으로서는 GPU 네이티브 인스트럭션 세트의 노출화로 향하고 있다. 같은 GPU 인스트럭션 세트를 계속해 제공·발전시키는 것으로, 일관된 프로그래밍 모델을 제공하려고 하고 있다. 종래의 GPU와는 명확한 차이다.
이것은 GPU의 방향성을 크게 바꾸는 요소를 가지고 있다. 그렇다고 하는 것은 종래와 같이 인스트럭션 세트의 계속성을 무시한 GPU 아키텍쳐의 확장을 할 수 없게 되기 때문이다. CPU와 같이 인스트럭션 세트의 일관성을 유지하면서 발전될 방향으로 장래의 AMD GPU 코어는 향하게 될 것 같다. 즉, GPU 아키텍쳐의 개발의 수법이 크게 바뀌는 것이다.
그 한편, 인스트럭션 세트의 일관성이 유지되는 것으로 소프트웨어층의 개발이 용이하게 된다. 어느 GPU 세대전용으로 개발한 native code의 소프트웨어가, 그대로 장래의 GPU에서도 달리는 것이 보호되기 때문이다. 코드의 최적화도 용이하게 된다.
그리고, 이것은 다음의 인스트럭션 세트 전쟁을 예견시킨다. 각사의 GPU의 네이티브 인스트럭션이 차이가 나기 때문에, 비유하고 모든 GPU 벤더가 인스트럭션 세트를 공개했다고 해도 binary level compatibility 은 없다. 그 때문에, 어플리케이션측이 GPU와 네이티브 인스트럭션을 사용하기 시작하면 인스트럭션 세트끼리의 싸움이 되기 시작한다. SSE vs 3DNow! 와 같은 인스트럭션 세트 분쟁이 다시 일어날 가능성이 있다. 그러나, 이번은 64-bit화에서의 x86-64(AMD64) 대 Yamhill 때에 같이 선행하는 AMD가 유리하게 될 가능성도 높다. 또, 적은 Intel는 아니고 NVIDIA일지도 모른다.
●CPU의 유저 모드 인스트럭션 세트로서 통합
또, AMD의 FUSION에서의 인스트럭션 세트의 사용가능화 에서는, CPU의 인스트럭션 세트 아키텍쳐안에 GPU 인스트럭션을 수중에 넣는 것이 적절하다고 생각하고 있는 일도 포인트다. Hester 의 비전을 좀 더 자세하게 설명하면 다음과 같이 된다.
「일반론으로서 coprocessor의 통합에는 2개의 방법이 있다. 하나는, CPU의 유저 모드 인스트럭션 세트 아키텍쳐에 통합해 버리는 방법, 이제 1개는 일종의 system resource로서 디바이스 드라이버등을 경유해 취급하는 방법. 이것들에는, 각각 이점과 불이익이 있다.
우선, 유저 모드 인스트럭션 세트안에 통합하기 위해서는, (CPU 메이커가) 특정의 기능과 아키텍쳐에 대해, 향후도 발전계속 시키는 것을 (유저에 대해서) 정당화할 수 없으면 안 된다.
인스트럭션 세트 아키텍쳐에 거두어 들이는 것의 이점은, 매우 낮은 오버헤드코스트로 그 기능을 사용할 수 있게 되는 것. 한편, 불리한 점은, 그 인스트럭션을 보호한다면 향후도 항상(그 인스트럭션으로 사용) 기능을 실리콘에 계속 넣지 않으면 안 되는 것이다.
그러니까, 통합할지 어떨지의 판단은 매우 신중하게 행할 필요가 있다. 또, 향후도 (통합하는 coprocessor의) 아키텍쳐를 논리적으로 일관성이 잡힌 방법으로 진화시킬 필요가 있다. 그러한 조건이 채워지면 유저 모드 인스트럭션 세트에 가세하는 것을 정당화 할 수 있을 것이다.
경우에 따라서는 올바른 대답은 Torrenza 형의 coprocessor에서의 디바이스 드라이버형 구조가 되는 케이스도 있다고 생각한다. 특수한 어플리케이션이 그 coprocessor 인스트럭션으로 프로세싱 하지만, 베이스 아키텍쳐에 명령을 던질 만큼 정당화할 수 없는 케이스가 있을 것이다. 그러한 기능은 Torrenza형의 coprocessor로 취급하는 요소의 하나가 된다고 생각하고 있다. Torrenza형의 경우는 디바이스 드라이버형의 스트럭쳐를 통해서 소프트웨어와 커뮤니케이션 할 것이다.
어느 쪽이 적절한가는, 일종의 티핑 포인트(Tipping Point:전환점)의 논의가 된다」
●GPU를 인스트럭션 세트 레벨로 CPU에 통합해 간다
AMD는, 어차피 GPU 인스트럭션 세트를 노출시킨다면 x86의 베이스 포맷안에 유저 모드의 확장 인스트럭션으로서 짜넣으려는 비전을 가지고 있는 것 같다. 이것은 보다 기본적인 레벨에서의 CPU와 GPU의 통합을 생각하고 있는 것이다. 이 모델에서는 x86 인스트럭션의 스트림에 짜넣어진 GPU 인스트럭션을 디코더가 GPU 코어에 발행한다고 추측된다.
현재는 CPU상의 런타임이 그래픽 인스트럭션이나 GPU전용 범용 인스트럭션을 리얼타임에 GPU 네이티브 인스트럭션에 변환. 변환이 끝난 네이티브 인스트럭션을, 버스를 경유해 GPU에 보내고 있다. 그러나, 인스트럭션 세트의 통합 후에는, CPU의 인스트럭션 디코더로 직접 GPU 네이티브 인스트럭션이 디코드되게 된다. 그 경우, 최종적으로는 GPU 코어는, CPU안의 GPU 기능으로 융합되어 갈 것이다.
Torrenza와 FUSION에는, 이와 같이 on-chip 이나 오프 칩의 차이 이상으로, 소프트웨어면에서의 차이가 있다.
그러나, 이 구상에서는, 그렇지 않아도 복잡한 x86 인스트럭션 세트 체계를 한층 더 복잡하게 해 그 결과, 인스트럭션 디코더의 부담도 늘리는 것을 의미한다. 이것은 문제는 아닌 것일까.
「x86의 유저 모드 인스트럭션 세트 포맷에는, 아직 충분한 작동코드 포인트가 남아 있다. 확장 인스트럭션을 더하는 것이 가능하다. 또, 인스트럭션 디코더는 현상황에서도 벌써 복잡하다. 그러니까, 한층 더 복잡한 시스템을 더해도 비교적 작은 변화에 지나지 않는다. 엔지니어는 충분히 가능하다고 말한다.
그러니까, 우리는 이런 종류의 문제에 대해서는 그만큼 걱정하고 있지 않다. 그것보다 중요한 문제는, 어떤 인스트럭션을 유저 모드 인스트럭션 세트에 포함시킬 것인가 라고 하는 점이다. 일단 coprocessor 인스트럭션의 기능은 계속 의지하게 된다. 그러니까 신중하게 행할 필요가 있다」(Hester)
●x86 CPU측으로부터 Torrenza형 coprocessor
AMD는 벌써 복잡한 x86 아키텍쳐이니까 그것을 확장한다면 문제는 없다고 보고 있는 것을 알 수 있다. 실제 프리픽스등으로 복잡한 가변장의 인스트럭션 세트는 현상황 에서도 인스트럭션 디코더에 있어 터무니없는 무거운 짐이 되고 있다. 이것을 변혁하려면 x86 인스트럭션 세트 자체를 일신 하는 이외 방법은 없다. 그렇다면, 현상황의 복잡도에 한층 더 조금 복잡한 시스템을 더해도 큰 변화는 아니라고 추측된다.
다만, 일단 서포트한 인스트럭션은 간단하게 잘라 버릴 수 없게 되어 버린다. 그러니까, x86 인스트럭션 세트 체계안에 있는 인스트럭션은 신중하게 선택할 필요가 있다. 이점은 인스트럭션 세트를 통합할 수 있는 coprocessor로 한정된다.
한편, Torrenza의 디바이스 드라이버 모델에서는 오버헤드는 있지만, 소프트웨어적으로는 용이한 통합이 된다. coprocessor측의 인스트럭션 세트의 포맷도, 자유롭게 할 수 있다고 하는 이점도 있다. 예를 들면, coprocessor에서는 VLIW(Very Long Instruction Word) 형 인스트럭션 세트를 취할 수도 있다.
「Torrenza형으로 디바이스 드라이버를 경유하는 경우는, 데이터는(호스트 프로세서로부터) coprocessor에 그대로 패스된다. 데이터 포맷은 coprocessor 독자로 상관없기 때문에 호환성에 대해 걱정할 필요는 없다.
x86 프로세서측에서 보면 컨트롤 블록(프로그램)은 단지 데이터로 결코 x86 프로세서상에서 실행되지 않는다. coprocessor 의 인스트럭션 포맷이나 그 외의 요소는 x86 프로세서로부터는 보이지 않고 coprocessor 에서 보인다. 그러니까, 컨트롤 블록은, 어떤 포맷에 정의하는 일도 가능해 coprocessor로 베스트 설계를 할 수 있다」라고 Hester 는 설명한다.
●CPU와 GPU의 물리적인 통합과 인스트럭션 레벨의 통합의 제휴
이 경우 포인트는 CPU와 GPU의 온 다이 통합이 인스트럭션 세트의 복합을 의미하는 것은 아니다는 점이다. 단일 다이상에 정리했다고 해도 양코어의 인스트럭션 세트를 Torrenza형에 따로 따로 분리할 수 있다. 시스템 on-chip(SoC) 어프로치로 단순하게 다이상에 CPU와 GPU를 배치할 뿐이라면, 인스트럭션 레벨의 통합은 필요하지 않다. 한편, 반대로 다이는 별도여도 인스트럭션 세트 로는 통합된 형태도 있을 수 있다.
그러나, CPU와 GPU의 실리콘상에서의 통합화가, 인스트럭션 세트의 통합의 중요한 열쇠인 것은 확실하다.
「CPU와 GPU를 통합하는 것으로, 처음으로 기능을(유저에게) 보호해 「좋아, 이것으로 유저 모드 인스트럭션 세트에 넣는 것을 정당화 할 수 있다」라고 결정할 수 있게 된다」라고 Hester 는 말한다.
즉, AMD는 coprocessor의 온 다이 통합이 인스트럭션 세트 레벨의 통합의 조건이라고 생각하고 있다.
무엇보다, 실제의 제품 레벨에서는 GPU 코어의 물리적인 통합이라고 인스트럭션 세트상의 통합은 시기가 어긋날지도 모른다. 또, GPU 코어의 마이크로 아키텍쳐상의 통합도, 인스트럭션 세트 레벨의 통합에 따라, 단계적으로 변화해 갈 가능성이 있다. 처음은, GPU 코어가 CPU 코어와는 분리되고 내부 크로스바로 접속된 형태이지만, 장래는 좀 더 융합이 진행된 아키텍쳐로 바뀌어 갈 가능성이 있다.
AMD의 비전에 따르면, FUSION 세대의 장래의 GPU 코어의 소프트웨어 모델은 CPU의 거기와 비슷하다. 네이티브 인스트럭션 세트가 명백하게 되어 x86 포맷에 받아들여져 일관성을 가져 인스트럭션이 보관 유지되어 간다. 당연 각종 미들웨어가 성장해 어플리케이션이 GPU 기능을 용이하게 사용할 수 있게 되어 간다고 예상된다.
PC 소프트웨어 모델의 경우 이러한 미들웨어가 확립하지 않으면 좀처럼 보급이 진행되지 않는다. 그 때문에 표준적인 API의 정비등이 중요해진다. 여기서, 요점이 되는 존재가 Microsoft인가, 그렇지 않으면 OpenGL ES등을 책정하는 단체 Khronos Group인가, 혹은 PeakStream와 같은 벤처인가는 아직 모른다. 그러나, AMD는 리더쉽을 취해 갈 필요가 있는 것만은 확실하다.
문제는 여기에 있다. AMD에서 약한것 중의 하나가 , 소프트웨어면 에서의 리더쉽을 취해 가는 것이기 때문이다. GPU 코어의 통합으로 칩 레벨의 통합 이상으로 곤란한 것은 아마, 이러한 소프트웨어면의 정비다. FUSION 프로세서가 AMD에 있어 큰 도전인 것은 이 점이다.
□관련 기사
【2007년 2월 27일】【해외】CPU와 GPU의 통합 프로세서로의 도전
http://pc.watch.impress.co.jp/docs/2007/0227/kaigai340.htm
【2007년 2월 15일】【해외】Intel의 차세대 CPU 「Wolfdale」와「CPU+GPU」
http://pc.watch.impress.co.jp/docs/2007/0202/kaigai333.htm
【1월 22일】【해외】AMD가“Fusion”프로세서와 옥타코아로의 진행 이유
http://pc.watch.impress.co.jp/docs/2007/0122/kaigai330.htm
□백 넘버
(2007년 2월 28일)
[Reported by 고토 히로시무(Hiroshige Goto)]
'IT분야 해외뉴스' 카테고리의 다른 글
| TDP 45 W판의 Athlon 64가 발매, 89 W판과 가격동일 (0) | 2007.03.06 |
|---|---|
| ■고토 히로시무의 Weekly 해외 뉴스■ (2007년 2월 2일) (0) | 2007.03.01 |
| ■고토 히로시무의 Weekly 해외 뉴스■ (2007년 1월 22일) (0) | 2007.03.01 |
| ■고토 히로시무의 Weekly 해외 뉴스■ (2007.2.27) (0) | 2007.03.01 |
| 45W Athlon 64 3500+ / 3800+ 발매 (0) | 2007.02.28 |