■고토 히로시무의 Weekly 해외 뉴스■
MIMD의 Larrabee와 SIMD의 GPU의 싸움
● MIMD 구성으로 캐쉬 계층을 갖추는 Larrabee
Intel은 다중코어 타입인 고효율 프로세서인 「Larrabee(라라비)」로 개개의 프로세서 코어가 개별의 인스트럭션을 실행하는 MIMD(Multiple Instruction, Multiple Data) 형의 구성을 채용한다. 「Larrabee는 MIMD 머신이며 컨벤셔널인 캐쉬 계층을 가진다. 이 두가지 점이 GPU와 다르다」라고 Intel의 Justin R. Rattner(져스틴·R·래트너) (Senior Fellow, Corporate Technology Group겸CTO, Intel)는 말한다.
그에 대해 현재의 GPU 대부분은 많은 쉐이더프로세서코어를 가지고 1개의 인스트럭션 유닛으로 제어하는 커다란 SIMD(Single Instruction, Multiple Data) 형의 구성을 취하고 있다. SIMD 구성되는 쉐이더프로세서의 수는 4개로부터 많은 경우에는 수십 코어에 오른다. 현재의 통합쉐이더형 GPU는 NVIDIA와 AMD(구ATI)의 어느쪽이나 커다란 SIMD 머신이 되고 있다.
그 때문에 아키텍쳐상의 구도로서는 SIMD GPU대 MIMD Larrabee의 싸움이 된다. 이것은 하이 퍼포먼스 컴퓨팅(HPC)의 세계에서 전개된 SIMD(벡터)와 MIMD(멀티 프로세서)의 어느 쪽의 어프로치가 우수할까의 논쟁을 재현 시킨다. 시스템 레벨의 SIMD대 MIMD의 구도가 이번은 on-chip 레벨로 반복해지는 것이다.
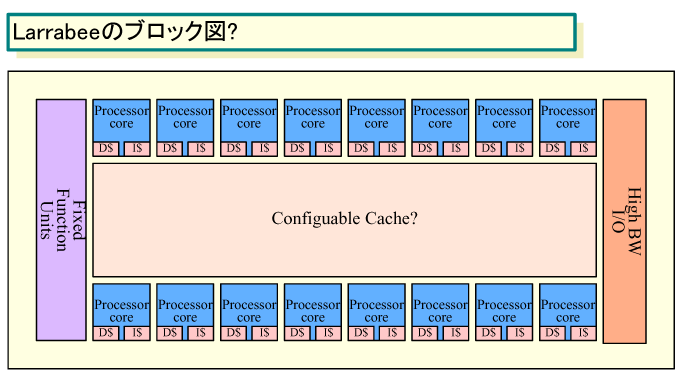
Larrabee의 블럭도?

IA의 프로그램성과 병렬성에 의해 고throughput 컴퓨팅을 가져온다
SIMD와 MIMD 양쪽의 접근에는 각각 이점과 난점이 있다. 일반적으로 MIMD형이 유연성이 높지만 SIMD형이 벡터 연산을 위해 효율이 높다. SIMD의 경우는 프로세서의 제어가 용이하게 되기 때문에 트랜지스터 카운트 에서 이론상의 퍼포먼스를 높게 하기 쉽다. 그러나 MIMD라면 큰 벡터에 구성하는 것이 어려운 태스크도 효율적으로 해낼 수가 있다. 각 thread가 타이트에 동기 하고 있는 경우는 SIMD가 유리하지만 반대로 인스트럭션 플로우(flow)가 조건 분기등에서 다른 패스로 나누어지는 경우에는 MIMD가 효율적이 된다. SIMD의 경우는 벡터 안에서 분기 패스가 다른 경우에는 양쪽 모두의 패스를 실행하는 등의 헛일이 생겨 버리기 때문이다.
프로그래밍면에서는 SIMD GPU에서는 연산 범위가 실제의 벡터장이 은폐 되고 있어 자동적으로 셋업 소프트웨어에 의해 벡터화가 행해지기 때문에 프로그래머측이 벡터장을 의식할 필요가 없다. 프로그램을 쓰는 측은 1개의 데이터 엘리먼트를 위한 프로그램을 쓰면 자동으로 다수의 데이터 엘리먼트에 대해서 병렬화 된다. 하지만 그 반면 런타임 소프트웨어에 의한 셋업에 방대한 시간 걸려 버린다.
그래픽 처리에서는 데이터간의 처리에 의존성이 없고 방대한 연산 성능이 요구되기 때문에 자연히 커다란 SIMD로 향했다. 그에 대해 Larrabee에서는 그래픽과 같은 데이터 병렬처리도 MIMD상에서 행하지만 보다 유연하게 다양한 처리를 커버하는 것을 목표로 하기 때문에 MIMD를 채용했다고 보여진다. 무엇보다 Larrabee도 MIMD 구성의 각 프로세서 코어안은 비교적 짧은 SIMD의 구성이 되고 있다고 보여진다.
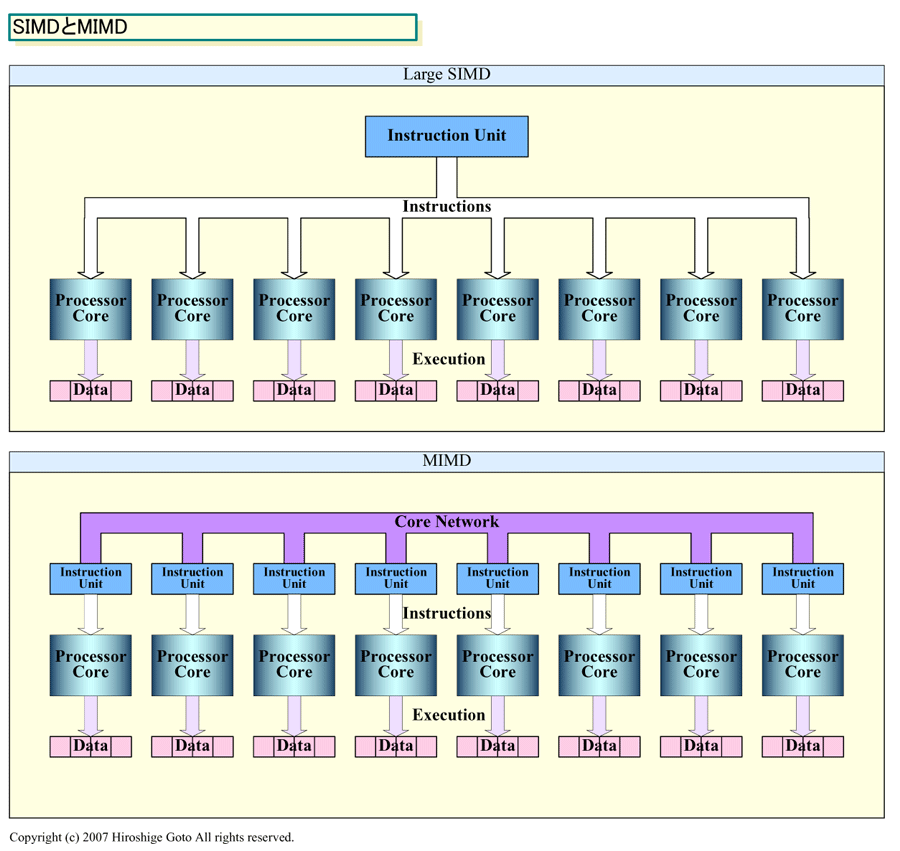
SIMD와 MIMD
덧붙여서, Intel의 경우는 통합 GPU 코어도 MIMD형이다. Intel Technology Journal(Volume 11 Issue 03)의 기사 「Accelerator Exoskeleton」를 보면(자), 8개의 EU가 독립한 구조가 되어 있어, 한층 더 각 코어의 4way SIMD 유닛이 4 하드웨어 thread 콘텍스트를 서포트하는 구조가 되고 있다. 유연성을 제일로 생각하는 사상은 GPU 코어에도 공통되고 있다고 보여진다.
또, GPU도, 리드&라이트 가능한 로카르메모리를 가지게 되기 시작했지만, CPU와 같은 일관성과 유연성이 있는 캐시 기억 장치는 아니다. 이러한 점을 보면(자), Larrabee가 목표로 하고 있는 것은, GPU의 난점을 커버할 수 있는 어프로치와 같다. 어떤 의미로 GPU의 약점인 부분을 찔렀던 것이 Larrabee라고 말할 수 있을지도 모른다.
●비슷하면서도 다른 Larrabee와 FUSION의 어프로치
Intel은 Larrabee의 MIMD 구성의 프로세서 코어가 IA(x86계) 인스트럭션 세트와 호환성을 가진다고 설명하고 있다. Intel의 Stephen L. Smith(스티브·L·스미스) (Vice President, Director, Digital Enterprise Group Operations, Intel)는 「Larrabee에서는 우리는 세계의 모든 디벨로퍼가 프로그램의 쓰는 법을 알고 있는 IA(x86계 인스트럭션 세트 아키텍쳐)의 이점을 살리는 것이 보다 좋은 솔루션이라고 판단했다. 보다 유연해 프로그램의 쓰는 법을 간단하게 이해할 수 있어 업계의 인프라를 이용할 수 있는 아키텍쳐를 실현할 생각이다」라고 말한다. 고효율의 프로세서에 IA인스트럭션 세트를 실장하려는 Larrabee의 아이디어다.
이점 증가와 혼란의 감소
그에 대해, AMD도 GPU 리소스를 CPU측의 인스트럭션 세트로부터도 이용할 수 있도록 한다고 한다. 구체적으로는 AMD가 발표한 SSE5 인스트럭션의 일부는 CPU 코어는 아니고 GPU 코어에 발행되어 실행되게 된다. GPU 자체에는 x86계 인스트럭션 세트는 실장하지 않지만 x86계 CPU 코어로부터 인스트럭션 레벨로 GPU 코어에 액세스 할 수 있도록 한다. GPU 코어에 대해서는 종래대로의 드라이버 모델에서의 액세스도 가능하게 유지한다.
또, AMD는 커다란 SIMD의 GPU 코어를 그대로 범용에 사용하려고는 생각하지 않았다. 최초의 FUSION는 차치하고 장래의 FUSION에서는 GPU의 연산 리소스를 보다 작은 벡터로 분해해 간다. 실제로는 FUSION의 벡터장은 Larrabee와 동일한 정도가 될지 모른다. SIMD와 MIMD의 사이에서의 최적인 밸런스를 취하면 최종적으로는 같은 결과가 될 가능성도 높다.
이렇게 해 보면 양자의 어프로치는 닮은 것처럼 보이지만 큰 차이가 있다. Intel의 Rattner씨는 다음과 같이 설명한다.
「우리가 바라고 있는 것은 Intel 아키텍쳐(IA)의 힘으로 그래픽 프로그래밍을 실현하는 것이다. 그러나 IA라고 말해도 데이터 병렬 아키텍쳐의 퍼포먼스를 실현하는 점에 Larrabee의 아키텍쳐상의 새로움이 있다.
어떻게 IA호환성을 유지하면서 (데이터 병렬 아키텍쳐의) 퍼포먼스를 실현할까. 그 점에 대한 기본적인 어프로치에 우리와 AMD/ATI와의 차이가 있다. 간단하게 말하면 그들은 CPU+GPU 월드를 목표로 하고 있다. 우리는 CPU 월드에 방대한 부동 소수점 연산 기능을 더하는 것을 목표로 하고 있다」
즉, AMD는 GPU를 GPU로서의 특성을 가능한 한 보관 유지한 채로 CPU측으로부터 잘 이용할 수 있도록 하려고 하고 있다. CPU에 있어서의 서브 프로세서 유닛인 GPU 코어 자체에 IA인스트럭션 세트는 실장하지 않는다. 생각하기에 coprocessor에 가깝다. 그에 대해 Intel은 Larrabee를 CPU의 진화형의 하나로 보고 있다. IA CPU의 진화형의 하나로서 Larrabee를 파악하고 있기 때문에 Larrabee 프로세서 코어를 IA인스트럭션 세트 베이스로 한다.
● Larrabee가 다음의 큰 인스트럭션 세트 확장
물론 Larrabee에서는 인스트럭션 세트 자체도 확장한다. 적어도 Intel의 Digital Enterprise Group은 Larrabee를 IA인스트럭션 세트의 다음번 레벨의 확장이라고 보고 있다. Patrick(Pat) P. Gelsinger(퍼트·P·겔 싱어) (Senior Vice President and General Manager, Digital Enterprise Group)는 다음과 같이 말한다.
「우리는 인스트럭션 세트 모델은 아키텍쳐 어프로치의 본질적인 부분이며 일관할 필요가 있다고 생각하고 있다. Cell B.E. 를 시작해로 한 어프로치가 성공하지 않은 것은 그것들이 인스트럭션 세트의 확장에 대한 일관한 생각을 가지고 있지 않기 때문이라고 생각하고 있다.
우리는 장래에 걸쳐서 인스트럭션 세트를 계속 한층 더 확장할 수 있다고 보고 있다. SSE4를 발표했지만 그 이후의 SSE의 정의도 진행하고 있다. 게다가 보다 큰 인스트럭션 세트의 확장도 Larrabee의 일부로서 진행하고 있다. 즉, ILP(Instruction-Level Parallelism)를 높일 뿐만 아니라 새로운 인스트럭션 세트 모델에 의해 벡터 레벨의 병렬성을 높여 간다. 내년(2008년)에는 인스트럭션 세트에 대해 좀 더 상세히 설명 할 수 있을 것이다」
1개의 인스트럭션 세트 아키텍쳐를 일관해 확장해 간다. 그것이 IA CPU의 아키텍트였던 Gelsinger씨의 기본적인 생각이며 지금 Intel의 CPU 전략의 기본이 되고 있다. IA(x86계)로 커버할 수 없는 area는 IA-64가 존재하지만 적어도 메인 스트림은 IA로 계속 커버한다. Larrabee와 같은 큰 인스트럭션 세트의 혁신도 그 범위내에 넣는다고 하는 비전과 같다.
Cell B.E. 를 인용하고 있는 것은 물론, Cell B.E. 의 SPE(Synergistic Processor Element)의 인스트럭션 세트가 Power 준거는 아니고 독자적인 인스트럭션 세트이기 때문이다. 기존의 Power를 계승 발전시키지 않았던 것 특수한 프로그래밍 모델을 뽑았던 것이 Intel의 시점으로부터 하면 실수라고 지적하고 있는 것이다. 물론, 이것은 트레이드 오프로 기존의 인스트럭션 세트를 계승하는 한 제약도 생긴다.
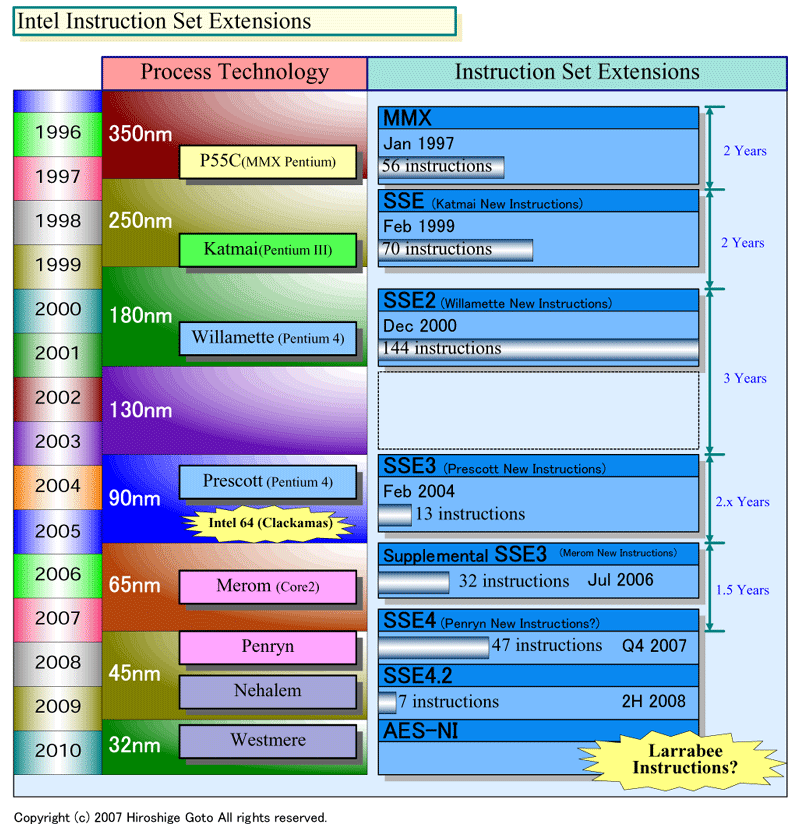
Intel Extruction Set Extensions
● 그래픽 전용으로 투입되는 최초의 Larrabee
IA인스트럭션 세트로 하이 고효율 컴퓨팅을 실현하는 Larrabee. 그러나 Intel의 Larrabee 계획의 축이 확실히 정해지고 있는가 하면 그렇지도 않다. 일례를 들면 Intel은 처음에는 Larrabee를 하이 퍼포먼스 컴퓨팅(HPC)등의 분야에 투입한다고 말하고 있었다. 그 때문에 시험판을 최초로 소량 출하한다고 할 계획이었다. 그러나, 현재의 Larrabee는 그래픽에 포커스 할 계획으로 변경되고 있다.
「Larrabee는 넓은 범위의 컴퓨팅 문제를 노리고 있다. throughput 컴퓨팅, 가시화, 재무 분석, HPC 등이다. 그러나, 이번에 발표한 것은 최초의 제품은 그래픽이 된다고 하는 것이다. 넓은 범위의 작업 부담량을 커버하는 제품군이지만 최초의 제품은 그래픽이다」(Gelsinger)
이 계획에서는 Larrabee는 우선 NVIDIA나 AMD/ATI의 GPU와 정면으로부터 부딪치게 된다. 그래픽에 포커스 해 아키텍쳐를 최적화한 GPU와 그래픽으로 부딪치는 것은 위험으로 보인다. 단순하게 그래픽만을 처리한다면 커다란 SIMD형이 트랜지스터 카운트 당의 효율이 좋아질 가능성이 높기 때문이다.
그 때문에, Intel은 전략적으로 Larrabee에서는 그래픽 플러스 알파를 구가한다고 추측된다. 거기서 부합 하는 것은 Intel에 의한 물리 시뮬레이션 소프트웨어 엔진 메이커의 HAVOK의 매수다. Intel이 물리 시뮬레이션 등도 효율적으로 실행할 수 있는 하드로서 Larrabee를 밀어 낸다고 하면 이 매수도 부합 한다. 다만, HAVOK 자체는 Larrabee와 같은 고thread 병렬 하드웨어를 향한 실장은 하지 않는다고 말해진다.
이렇게 해서 전체를 보면 Intel에 있어 그래픽 용도의 GPU 코어의 통합은 최초의 스텝에서 CPU로서의 확장을 주목적으로 생각하고 있는 것을 잘 알수 있다. 그리고 CPU로서의 인스트럭션 세트 확장의 흐름 위에 Larrabee가 있다. 자연스러운 흐름으로는 장래적으로 GPU 코어는 아니고 Larrabee형의 프로세서 코어군을 CPU에 통합해 그래픽 태스크도 거기에 시키게 될 것이다.
그러나 Intel의 이 전략이 잘 되어가는지 어떤지는 아직 모른다. 하이 throughput 프로세서 코어에 IA인스트럭션 세트를 실장하는 것의 어떤지에 대해서는 아직 결론이 나와 있지 않다. 프로그램 하기 쉽다는 부분에 의해 희생이 되는 부분이 크다고 예상되기 때문이다. 시금석은 최초의 독립된 장치로서의 Larrabee가 될 것이다.
'IT분야 해외뉴스' 카테고리의 다른 글
| AMD 차세대 서버 플랫폼 Maranello (0) | 2008.05.21 |
|---|---|
| Intel에 대항하기 위한 AMD의 서버 CPU 로드맵 갱신 (0) | 2008.05.13 |
| Intel Nehalem 과 AMD FUSION CPU+GPU 통합의 차이 (0) | 2007.10.13 |
| 강력한 제조 공정과 45nm 제품으로 Intel에 도전하는 AMD (0) | 2007.10.05 |
| INTEL이 목표로 하는 Nehalem에서의 GPU와 CPU의 통합 (0) | 2007.10.05 |