■고토 히로시무의 Weekly 해외 뉴스■
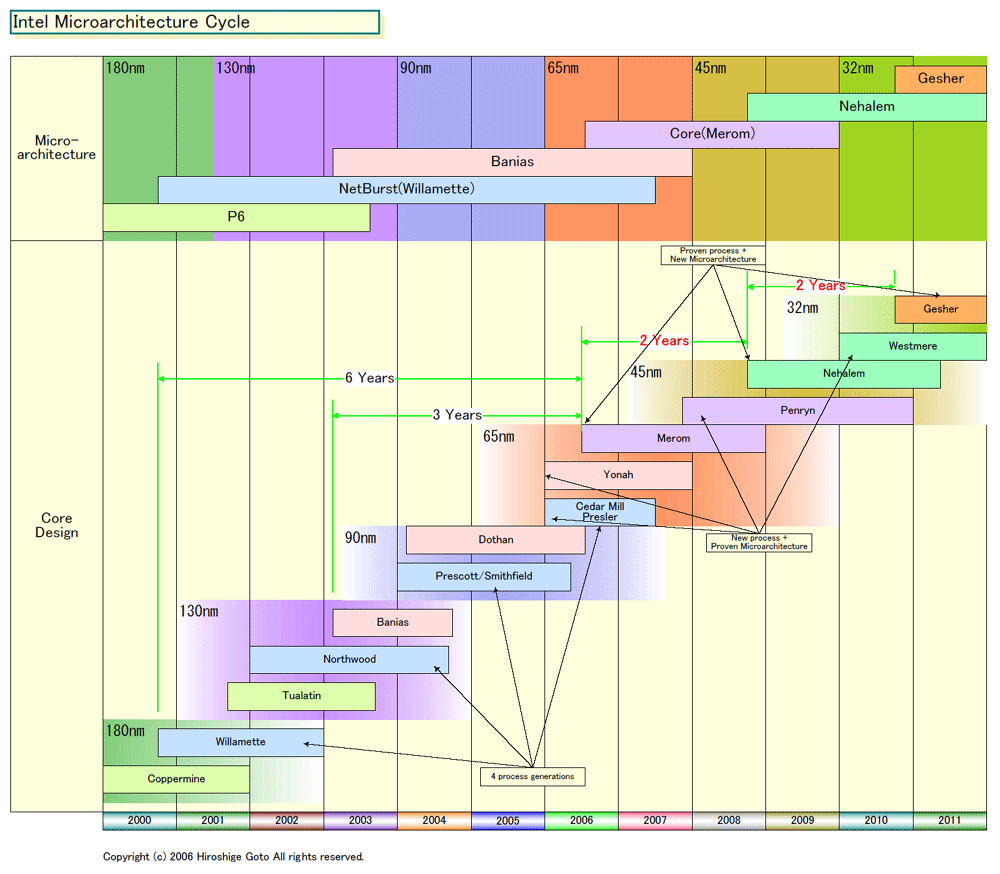
Intel의 마이크로 아키텍쳐 개혁 「Nehalem」
● Intel이 IDF전에 Nehalem 개요 공개
Intel이 차세대 마이크로 아키텍쳐 CPU 「Nehalem(네할렘)」의 개요를 분명히 했다.
Nehalem는 메모리 인터페이스를 통합해 시리얼 기술의 인터커넥트 「CSI」를 복수 탑재한다. CPU 코어수는 1에서 8 코어까지의 스케일을 가진다. 또, 각 CPU 코어는 Hyper-Threading과 같은 기술로 2 thread를 실행할 수 있다. 그 때문에 8 코어의 Nehalem에서는 16 thread를 실행할 수 있다.

CPU 코어는 현재의 「Core Microarchitecture(Core MA)」와 같이 4 인스트럭션을 디코드&발행&리타이어 할 수 있는 아키텍쳐이다. 또, 복수 레벨의 공유 캐쉬를 갖춘다. 클라이언트전용에는 GPU 코어를 통합한 버젼도 제공한다. Nehalem은 45 nm프로세스로 제조해서 최초의 생산은 2008년 중반이 된다.


● Nehalem에서는 옥타코어가 등장
Nehalem은 싱글 코어로부터 옥타코아(Octa-core)까지의 스케일을 갖는다고 한다. 1개의 CPU에 탑재되는 CPU 코어수는 1~8 코어까지의 바리에이션이 있다. 다시말해 싱글코어, 듀얼코어, 쿼드코어, 옥타코아의 제품 구성이 된다고 추정된다.
Nehalem의 옥타코어에 대해서는 1개의 CPU 다이(반도체 본체)에 통합한 싱글 다이인가, 2개의 CPU 다이를 패키지상에서 접속한 듀얼 다이인가에 대해서는 아직 명확하지않다.
「옥타코어 탑재 디테일은 아직 밝힐 수가 없다. 우리회사는 최신 제품으로 보여지도록 패키지 테크놀러지로 2개의 실리콘 다이를 통합하는 능력도 가지고 있다. 이러한 능력은 향후에도 사용한다」라고 Intel의 Stephen L. Smith(부사장겸데스크탑·플랫폼·오퍼레이션즈 디렉터, Intel)는 설명한다.

Intel과 AMD의 65 nm프로세스의 쿼드코어는 사이즈가 같다. AMD의 「Barcelona(바르셀로나)」가 283평방 mm, Intel의 Kentsfield(켄츠필드) 가 286평방 mm. 하지만, AMD는 싱글 다이에 정리하고 있는데, Intel은 143평방 mm의 다이 2개를 패키지내에서 통합하고 있다.
복수 다이를 1 패키지에 거두는 다중 칩 모듈(MCM) 기술은 이전에는 제품 비율상의 불리함이 있었지만 Intel은 현재 그 문제는 해소했다고 한다. MCM화에서의 제품 비율의 불리함이 적으면 2 다이가 생산성은 높다. 그러나, 1개의 다이에 통합하는편이 퍼포먼스/소비 전력으로는 유리하다.
이 트레이드 오프 생각이 AMD와 Intel에서는 다르다. Intel은 현재 MCM으로 멀티 코어화를 선행시켜 다음 프로세스에서 싱글 다이로 이행 시킨다고 하는 전략을 취하고 있다. 그러면, CPU 자체의 설계도 공유화할 수 있기 때문에 설계 코스트나 기간도 단축할 수 있다.
그에 대에 AMD는, 싱글 다이에 통합한 네이티브 멀티 코어화의 어드밴티지에 집착하고 있다. 그 때문에, CPU 설계 자체를 모듈러화해 멀티 코어의 파생 설계를 간단하게 개발할 수 있도록하고 있다. Intel CPU는 모듈러 설계가 되지 않기 때문에 파생 설계에는 AMD보다 시간이 걸린다고 추정된다.
Intel과 AMD의 분화가 Nehalem 세대에도 계속된다고 하면 Intel의 Nehalem의 옥타코어는 싱글 다이는 아니고 듀얼 다이가 될 가능성이 높다. 지금까지의 흐름을 생각하면 2 다이가 자연스러운 방향이다. Nehalem의 신FSB인 CSI도 멀티 다이화에서는 유효하게 작용한다.
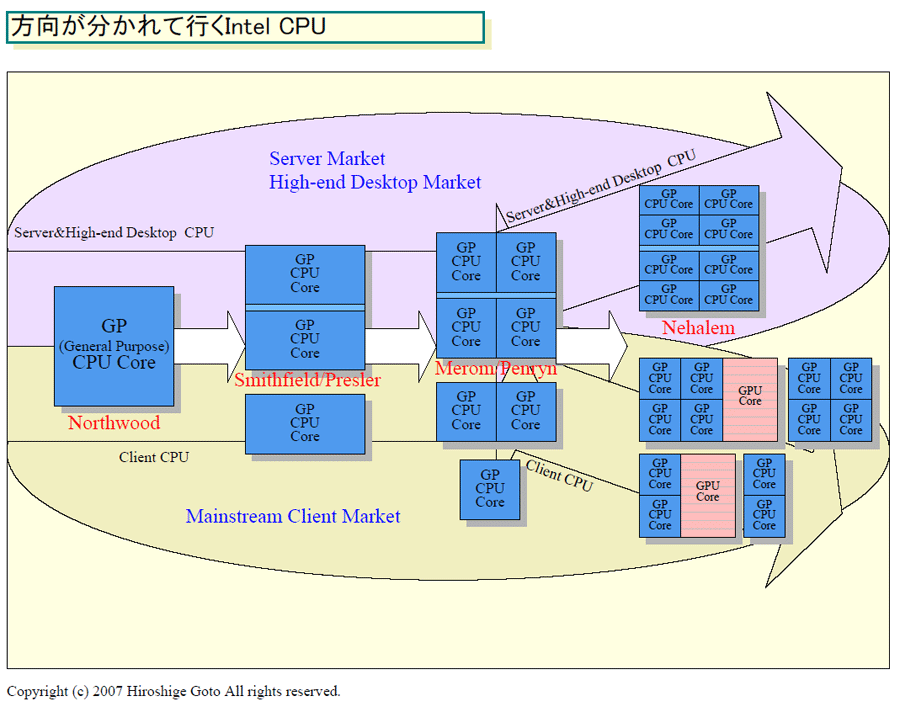
● 패키지내에서 CSI로 접속하는 것으로 듀얼 다이가 용이하게
Nehalem은 시리얼 기술의 칩간 고속 인터커넥트를 탑재한다. 종래의 패러렐 기술의 FSB(Front Side Bus)로부터 단번에 시리얼 기술로 점프 한다. 이 시리얼인터커넥트 CSI는 Intel CPU 공통의 인터커넥트가 되어 간다고 말하고 있다.
「Nehalem에 탑재하는 것은 고속의 시리얼인터커넥트이다. 오늘날의 시스템보다 광대역이 된다. 또, 프로세서간 접속하는 경우에는 coherency를 취하는 것이 가능하다. 1에서 4 링크 사이에. 또, I/O디바이스와의 접속도 행한다. 여전히 유연한 I/O링크가 필요하기 때문이다」라고 Smith는 설명한다.
현재 Intel 멀티 다이형의 멀티 코어 CPU의 경우 공유 버스형의 FSB를 패키지내에서 분기 시켜 2개의 CPU 다이를 접속하고 있다. 이것이, FSB 고속화 장벽의 하나가 되고 있다. 그러나, CSI가 되는 곳에서는 문제가 해결된다.
CSI 베이스의 CPU의 경우 CPU 패키지 안에서 CPU 다이 끼리 CSI의 1 링크를 사용해 접속할 수 있다. 역으로 말하면 CSI는 point-to-point 접속이므로 그렇게 하지 않으면 멀티 다이화를 할 수 없다.
Nehalem는 복수의 CSI를 갖추기 때문에 1 링크를 CPU끼리의 동기화 접속에 사용 다른 링크를 I/O접속이나 CPU 간접속에 사용한다. 멀티 프로세서판의 경우는 2개의 다이 CSI 링크를 각각 밖에 내 멀티 링크를 실현한다. 싱글 프로세서의 경우는 복수의 CSI 링크중 1개를 다이간의 접속에 별도인 링크를 1개 I/O칩 접속에 내는 것으로 대응할 수 있다. 이러한 구성이 추정된다.
Intel은 차례차례 IA-64 CPU인 「Tukwila」에서도 똑같이 CSI에 의한 2 다이 접속을 행한다고 말해지고 있다.
CSI에서의 다이 간접속은 MCM 설계상에서 이점이 있다. 멀티 다이의 경우 냉각을 생각하면 가능한 한 2개의 다이를 근처에 배치해 히트 싱크의 중앙에 위치시키는 편이 좋다. 현재의 패러렐 FSB의 경우 배선 면적이 크기 때문에 이러한 구성은 어렵다. 그러나, CSI의 경우는 배선이 용이하기 때문에 2개 다이의 배치가 보다 용이하게 된다고 추정된다.
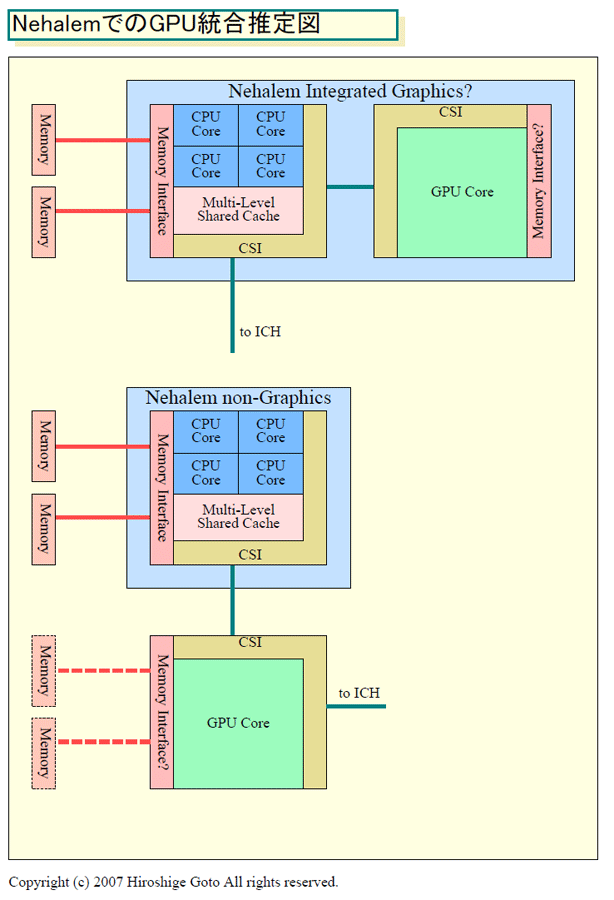
● 메모리콘트롤러를 CPU 측에 내장
Nehalem에서는 메모리콘트롤러를 통합한다. PC전용에서는 DDR3 메모리인터페이스를 서버전용에서는 FB-DIMM 인터페이스를 통합한다고 보여진다.
JEDEC(미국의 전자 공업회 EIA의 하부조직으로 반도체의 표준화 단체)의 DRAM 로드맵에서는 DDR3 세대가 약간 길어질 가능성이 예상되고 있다. 그 때문에 Nehalem 아키텍쳐(32 nm의 Westmere도 포함한다)의 클라이언트 PC에서는 DDR3가 표준으로 된다고 예상된다. DDR3에서는 듀얼메모리채넬이 된다고 추정된다. 광인터페이스폭의 DDR3 아키텍쳐에서는 듀얼 채널보다 넓은 인터페이스를 저비용에 탑재하는 것이 어렵기 때문이다.
DRAM은 데이터 전송 레이트가 올라도 메모리레이턴시는 개선되지 않는다. 그 때문에 CPU의 성능이 오르는 것에 따라 메모리레이턴시가 CPU 퍼포먼스를 방해하게 된다. DRAM 인터페이스의 통합은 CPU에 있어 필연적인 흐름이다.
한편, 서버에서는 시스템 메모리 탑재량이 필요하게 된다. 그 때문에, 데이지체로 DIMM를 접속할 수 있는 FB-DIMM 인터페이스가 유용이 된다. FB-DIMM에서 메모리레이턴시는 희생이 되지만 그 대신 메모리 탑재량과 메모리 대역의 양쪽 모두를 확보할 수 있다.
무엇보다 Nehalem 세대에는 메모리인터페이스를 CPU 에 통합하기 때문에 위상기하학이 바뀐다. AMD의 Opteron과 같이 CPU 개수를 늘리면 거기에 연동해 메모리체널수가 증가하게 된다. 그 때문에, FB-DIMM이 아니라도 시스템 메모리 탑재량을 늘리기 쉽다. DDR2/DDR3 인터페이스라고 하는 선택사항도 있지만 현재 Intel은 서버에서는 FB-DIMM 노선을 견지 하고 있다.
원래, CSI 세대 CPU에서 Intel은 IA-32로 IA-64의 양서버 CPU의 소켓과 칩 셋을 통합할 예정이었다. 그 때 플랜에서는 IA-32로 IA-64의 양CPU로 CSI와 FB-DIMM의 인터페이스를 공유화하는 것으로 플랫폼 통합을 가능하게 되어 있었다. 현재도 칩셋 레벨에서는 호환되는 플랜이 되고 있다고 한다.
멀티 다이로 옥타코어를 실현하는 경우 메모리인터페이스를 일부 비활성화 한다고 추정된다. PC전용의 싱글 코어의 경우 DDR3라면 마스터측 CPU 다이를 사용해 슬레이브측 CPU 다이의 메모리인터페이스는 비활성화 한다고 추정된다. 서버전용의 FB-DIMM의 경우는 퍼포먼스를 최대로 한다면 각각의 다이로부터 2 채널씩 4개의 FB-DIMM 채널을 사용한다고 생각된다.
● Hyper-Threading 이 restore하는 Nehalem 코어
Nehalem CPU 코어는 Core MA와 같이 4 인스트럭션 출력. Intel은 인스트럭션 출력수를 늘려 인스트럭션 레벨의 병렬성(ILP:Instruction-Level Parallelism)을 올리려고는 시도하지 않았다. 이것은 4 인스트럭션 출력 이상으로 해도 인스트럭션 스케줄링을 따라잡을수 없기 때문에 실효 ILP를 끌어올릴 수가 없기 때문이라고 추정된다.
그러나, Nehalem에서는 각 CPU 코어에 Hyper-Threading과 동종의 「SMT(Simultaneous Multithreading)」가 탑재된다. 「각각의 코어가 2 thread를 실행할 수 있다」(Smith)이라고 한다. 사이마르테니아스(?)이므로 2개의 thread 인스트럭션을 동시에 CPU 실행 파이프라인에 혼재시켜 실행할 수 있다.
SMT는 메모리레이턴시를 은폐 해 CPU 코어 내부의 실행 유닛의 빈 곳을 묻는 것으로 CPU 코어를 Busy로 유지하는 것을 가능하게 한다. SMT를 가지지 않는 경우 캐쉬 미스로 메모리 접근 stall이 발생했을 경우는 CPU 코어가 상당한 사이클로 건너서 아이들이 되어 버린다. 그러나, SMT에 의해 아이들 상태를 hread로 묶을 수가 있다. 물론, 그 만큼 액티브 thread가 있어야 한다는 전제가 있다.
SMT는 힐즈에서 설계해서 NetBurst 아키텍쳐로 도입된 기술. 같은 힐즈에서 설계하는 Nehalem에서 채용하는 것은 자연스러운 흐름이다. Core MA의 일부가 밝혀진 2005년 가을의 IDF에서 Intel의 Patrick(Pat) P. Gelsinger(퍼트·P·겔 싱어) (Senior Vice President and General Manager, Digital Enterprise Group)는 Core MA에 Hyper-Threading가 포함되지 않는 점에 대해 다음과 같이 말하고 있었다.
「Hyper-Threading이 유효하지 않다고 하는 것은 아니다. 소비 전력이나 효율등의 트레이드 오프로(Core MA에 Hyper-Threading를 탑재하지 않는다고 한다) 결정을 내렸다. 그러나, 장래에는 Hyper-Threading은 여전히 유용해 어떤 시점에 돌아올 것이다.
현재의 어플리케이션은 아직 thread화에의 이행이 빠른 단계에 있다. 그에 대해 듀얼 코어로 듀얼 프로세서 구성에서는 4 코어로 4개 이상의 액티브 thread가 없으면 Hyper-Threading를 탑재해도 효과가 적다. 그러나, 4 코어로 8 액티브 thread가 되면 Hyper-Threading은 매우 효율적이다. 그리고, 어플리케이션의 thread수는 장래에 증가해 간다고 예상하고 있다」
힐즈는 Gelsinger의 Digital Enterprise Group에 포함되어 있다. 그 때문에, 이러한 thread화의 예측의 바탕으로 SMT를 탑재해 왔다고 추정된다.
각 CPU 코어가 2 thread를 실행할 수 있기 때문에 듀얼 코어의 Nehalem는 4 thread 쿼드 코어는 8 thread, 옥타코어는 16 thread를 동시 실행할 수 있다. 옥타코어의 4 way 시스템에서는 64 액티브 thread를 실행할 수 있게 된다.
동시 실행할 수 있는 thread수가 증가하기 때문에 Nehalem 세대로는 4 way보다 2 way 듀얼 프로세서 시스템으로의 경사가 보다 강해진다고 추정된다. 멀티 코어+SMT로 thread 병렬성이 올라도 소프트웨어의 지연이 생기는 경우는 적어진다.
또, Nehalem의 파이프라인이 Core MA와 같이 비교적 높은 효율의 구조가 되고 있었을 경우는 실행 유닛의 아이들 상태가 적게 된다. 파이프라인의 효율이 나쁜 NetBurst 아키텍쳐보다는 SMT의 이익은 적다고 추정된다.
● Application Targeted Accelerators(ATA) 인스트럭션을 갖추는 Nehalem
Intel은 45 nm세대의 Core MA의 CPU 「Penryn(펜린)」으로 SSE4 인스트럭션을 추가한다. Nehalem에서는 Penryn과 같이 SSE4 인스트럭션을 탑재해 한층 더 「Application Targeted Accelerators(ATA)」인스트럭션을 갖춘다.
Gelsinger는 전회의 IDF에서 45 nm세대로는 어플리케이션에 특화한 특수한 가속기 인스트럭션 ATA를 더하는 것을 밝히고 있다. Intel이 최초로 탑재하려고 하고 있는 것은 「Cyclic Redundancy Check (CRC:순회 장황 검사)」의 가속화. CRC는 데이터 완전성 즉, 데이터가 파손하고 있을지 어떨지를 체크하는 구조. 대상으로 하는 데이터로부터 생성되는 CRC 밸류의 체크를 실시하는 인스트럭션 「CRC32」를 탑재한다고 한다.
CRC는 통신이나 스토리지로 잘 사용되고 있어 Intel도 네트워크스트레이지를 타겟으로 한다고 설명하고 있다. Intel에 의하면, 「iSCSI(Internet Small Computer System Interface)」나 「RDMA(Remote Direct Memory Access)」라고 하는 스토리지의 데이터트랜스퍼프로트콜의 액셀러레이트가 주목적이라고 한다. 현재는 이러한 프로토콜 처리를 CPU off-road 하는 전용 가속기가 있다. Nehalem에서는 그 가속기를 내장하게 된다.
전회 발표된 2번째의 가속기 인스트럭션은 대규모 데이터셋의 서치전용 인스트럭션 「POPCNT」. Population Count 인스트럭션으로 오퍼랜드중의 비트셋의 수를 센다. Intel은 응용의 예로써 게놈마이닝, 자필 인식, 허밍 알고리즘등을 들고 있다. Intel은 가속기의 통합을 이 2개로부터 시작하는 것 같다.
● 복수 레벨의 공유 캐쉬를 갖추는 Nehalem
Nehalem 코어의 그 외의 특별한 사항에 대해서는 밝혀지지 않았다. 그러나, 이전 Intel의 Justin R. Rattner(저스틴·R·라트나) (Intel Senior Fellow, Director, Corporate Technology Group)은 「Macro-Fusion이 향후 베이스가 되어 간다」라고 말하고 있어 Core MA로 도입된 Macro-Fusion등의 테크닉은 그대로 계속된다고 보여진다.
Intel은 멀티 코어상에서의 multi-thread 실행을 용이하게 하기 위한 「Transactional Memory」의 연구도 열심히 권하고 있다. Transactional Memory는 소프트웨어에서도 탑재할 수 있지만 CPU의 캐쉬 하드웨어 측에도 대응하는 기능을 갖추는편이 효율이 올라간다. Transactional Memory는 다음 멀티 코어의 큰 마이크로 아키텍쳐상의 개혁이지만 Nehalem에서 시간이 맞을지 어떨지는 모른다.
Nehalem에서는 CPU 측에 멀티 레벨의 공유 캐시(Multi-Level Shared Cache)를 탑재한다고 한다. L1캐시는 공유로 하기 어렵기 때문에 L2와 L3를 공유 캐시로서 갖춘다고 예상된다. AMD는 다음 「Barcelona(바르셀로나)」세대라도 데스크탑과 서버 CPU에서는 L2캐시를 코어 단위로 가져가고 L3를 공유 캐시로 한다. Intel의 캐시 구성은 이것과는 다르지만 데스크탑에서도 L3캐시가 들어 올 가능성이 있다.
컴퓨터의 메모리 계층은 메모리 접근과 CPU 성능의 갭이 퍼지는 것에 따라 확대하고 있다. 일정한 지연시간으로 액세스 할 수 있는 캐시 량에는 한계가 있기 때문에 캐시를 증량 하려고 하면 캐시 계층을 깊게 하게 된다. Nehalem 세대의 캐시가 모두 SRAM인지 별도인 메모리아키텍쳐를 생각하고 있는지는 아직 밝혀지지 않았다. 그러나, Intel의 경우는 지금까지의 연구 등을 보면 SRAM일 가능성이 높다.
이 외, Intel은 Nehalem에 GPU 코어를 통합하는 일도 밝히고 있다. 그러나, AMD의 CPU와 GPU 통합 프로젝트 「FUSION(퓨전)」과는 미묘하게 스탠스의 차이가 보인다. 다음에은 그 점을 분명히 하고 싶다.
(2007년 3월 30일)
[Reported by 고토 히로시무(Hiroshige Goto) ]
원본출처 : http://pc.watch.impress.co.jp/docs/2007/0330/kaigai348.htm
'IT분야 해외뉴스' 카테고리의 다른 글
| ■모토아자부 하루오의 주간 PC핫 라인■ (2007.4.3) (0) | 2007.04.03 |
|---|---|
| ■오오카와라 카츠유키의 「PC 업계, 동분서주」■ (2007.4.2) (0) | 2007.04.02 |
| ■야마다 쇼헤이의 Re:config.sys■ (2007.3.30) (0) | 2007.03.30 |
| Intel, 45 nm프로세서 차기 CPU 「Penryn」 상세 공개 (0) | 2007.03.29 |
| ■고토 히로시무의 Weekly 해외 뉴스■ (2007.3.29) (0) | 2007.03.29 |